

Dans cet article, vous découvrirez grâce à un cas pratique comment :
-
Créer et gérer des tables delta avec Spark
-
Utiliser Spark pour interroger et transformer des données dans des tables delta
-
Utiliser des tables delta avec le streaming structuré Spark
Vous avez besoin d’un compte scolaire ou professionnel Microsoft pour réaliser cet exercice. Si vous n’en avez pas, vous pouvez vous inscrire pour un essai de Microsoft Office 365 E3 ou version ultérieure .
Introduction
En de terme simple, le DELTA LAKE est cette couche de stockage ajouté à votre lac de donnée (sur spark) qui va vous permettre d’intérroger et traiter vos données comme vous le feriez dans votre SGBD relationnelle.
L’utilisation directe des API Delta Lake ne sont pas nécessaire dans Fabric, mais une compréhension de l’architecture du metastore Delta Lake peut améliorer la création de solutions analytiques avancées sur Microsoft Fabric.
Dans Microsoft Fabric, les tables dans les Lakehouses sont appélées des tables Delta et sont identifiablent par l’icône Delta triangulaire (▴) sur les tables dans l’interface utilisateur des lakehouses (image ci-dessous)
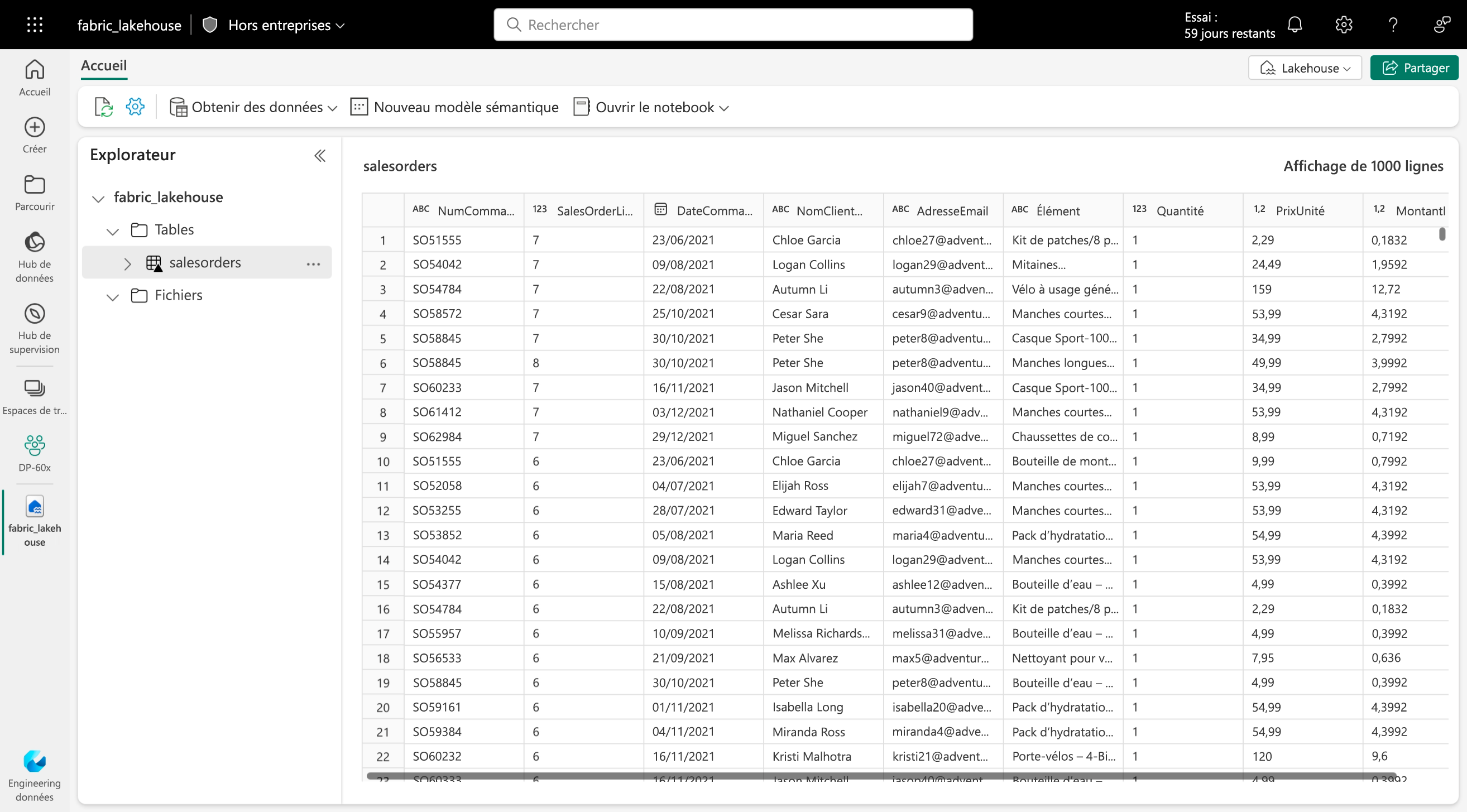
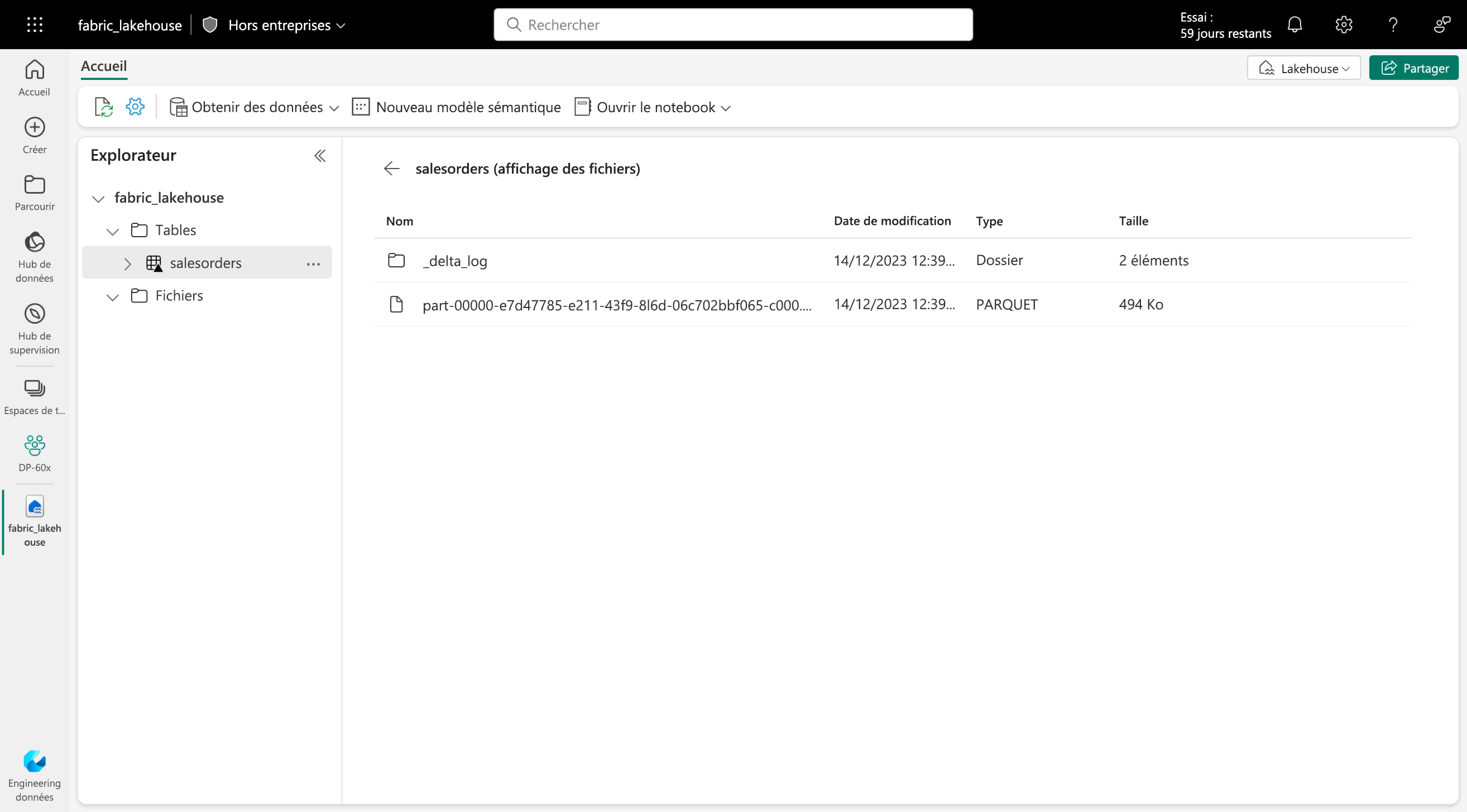
Un petit secret😉 : Les tables Delta n’existent pas physiquement en mémoire, elles sont des abstractions de schéma sur des fichiers de données stockés au format Delta. En fait, pour chaque table, le lakehouse stocke un dossier contenant des fichiers de données Parquet et un dossier _delta_Log dans lequel les détails de transaction sont journalisés au format JSON. (Voir l’image)
Les avantages d’utiliser des tables Delta de Microsoft Fabric sont les suivants :
- Vous disposez des tables relationnelles dans lesquels vous pouvez sélectionner, insérer, mettre à jour et supprimer (CRUD), des lignes de données de la même façon que dans un système de base de données relationnelle.
- Prise en charge des transactions ACID. Les bases de données relationnelles sont conçues pour prendre en charge les modifications de données transactionnelles qui fournissent l’atomicité (transactions terminées sous forme d’une unité de travail unique), la cohérence (les transactions laissent la base de données dans un état cohérent), l’isolation (les transactions in-process ne peuvent pas interférer entre elles) et la durabilité (lorsqu’une transaction se termine, les modifications apportées sont persistantes). Delta Lake apporte cette même prise en charge transactionnelle à Spark en implémentant un journal des transactions et en appliquant une isolation sérialisable pour les opérations simultanées.
- Contrôle de version des données et suivi de l’historique dans le temps. Étant donné que toutes les transactions sont enregistrées dans le journal des transactions, vous pouvez suivre plusieurs versions de chaque ligne de table et même utiliser la fonctionnalité de suivi de l’historique pour récupérer une version précédente d’une ligne dans une requête.
- Prise en charge des données de traitement par lots et de diffusion en continu. Bien que la plupart des bases de données relationnelles incluent des tables qui stockent des données statiques, Spark inclut la prise en charge native des données de diffusion en continu via l’API Spark Structured Streaming. Les tables Delta Lake peuvent être utilisées en tant que récepteurs (destinations) et sources pour la diffusion en continu de données.
- Formats standard et interopérabilité. Les données sous-jacentes des tables Delta sont stockées au format Parquet, qui est couramment utilisé dans les pipelines d’ingestion de lac de données. En outre, vous pouvez utiliser le point de terminaison d’analytique SQL pour le lakehouse Microsoft Fabric afin d’interroger des tables Delta en SQL.
Table managée : cela signifie que la définition de table dans le metastore et les fichiers de données sous-jacents sont gérés par le runtime Spark pour le lakehouse Fabric. La suppression de la table supprime également les fichiers sous-jacents de l’emplacement de stockage Tables pour le lakehouse.
Tables externes: Cela signifie que la définition de table relationnelle dans le metastore est mappée à un autre emplacement de stockage de fichiers. La suppression d’une table externe du metastore de lakehouse ne supprime pas les fichiers de données associés.
CAS PRATIQUE : UTILISEZ DES TABLES DELTA DANS APACHE PARK
1. Créer un espace de travail
Avant de travailler avec des données dans Fabric, créez un espace de travail avec la version d’essai Fabric activée.
- Sur la page d’accueil de Microsoft Fabric , sélectionnez Synapse Data Engineering .
- Dans la barre de menu de gauche, sélectionnez Espaces de travail (l’icône ressemble à 🗇).
- Créez un nouvel espace de travail avec le nom de votre choix, en sélectionnant un mode de licence qui inclut la capacité Fabric ( Trial , Premium ou Fabric ).
-
Lorsque votre nouvel espace de travail s’ouvre, il devrait être vide.
2. Créez un lakehouse et téléchargez les données
Maintenant que vous disposez d’un espace de travail, il est temps de créer un lac de données pour les données que vous allez analyser.
-
Dans la page d’accueil de Synapse Data Engineering , créez un nouveau Lakehouse avec le nom de votre choix.
Après environ une minute, une nouvelle maison au bord du lac vide. Vous devez ingérer certaines données dans le data Lakehouse pour analyse. Il existe plusieurs façons de procéder, mais dans cet exercice, vous allez simplement télécharger un fichier texte sur votre ordinateur local (ou sur la machine virtuelle de votre laboratoire le cas échéant), puis le télécharger sur votre Lakehouse.
-
Téléchargez le fichier de données pour cet exercice à partir de
https://github.com/MicrosoftLearning/dp-data/raw/main/products.csv, en l’enregistrant sous le nom products.csv sur votre ordinateur local (ou sur la machine virtuelle de l’atelier, le cas échéant). -
Revenez à l’onglet du navigateur Web contenant votre Lakehouse et dans le menu … du dossier Fichiers du volet Explorateur , sélectionnez Nouveau sous-dossier et créez un dossier nommé products .
- Dans le menu … du dossier products , sélectionnez Upload et Upload files , puis téléchargez le fichier products.csv depuis votre ordinateur local (ou la machine virtuelle de laboratoire le cas échéant) vers Lakehouse.
-
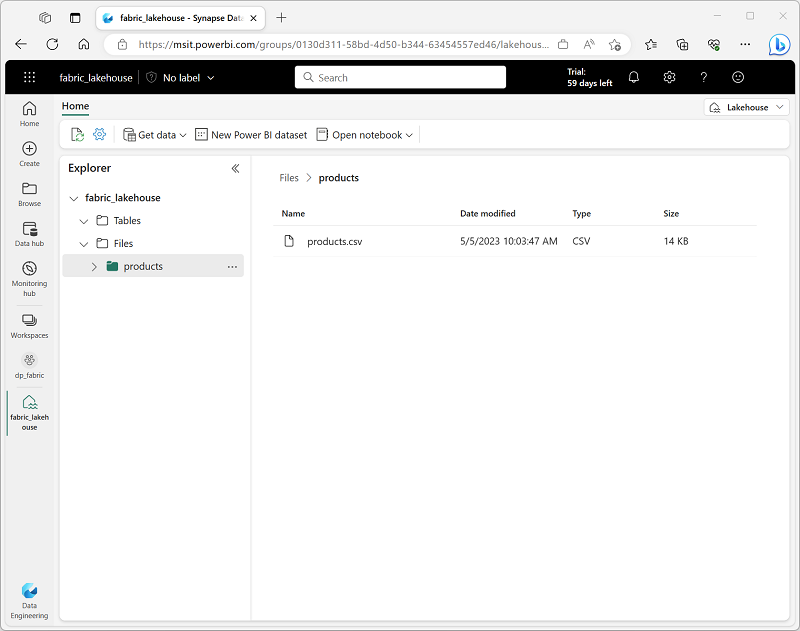
Une fois le fichier téléchargé, sélectionnez le dossier des produits ; et vérifiez que le fichier products.csv a été téléchargé, comme indiqué ici :
3. Explorez les données dans un dataframe
-
Sur la page d’accueil , lors de l’affichage du contenu du dossier products dans votre datalake, dans le menu Ouvrir le notebook , sélectionnez New notebook .
Après quelques secondes, un nouveau bloc-notes contenant une seule cellule s’ouvrira. Les blocs-notes sont constitués d’une ou plusieurs cellules pouvant contenir du code ou du markdown (texte formaté).
- Sélectionnez la cellule existante dans le bloc-notes, qui contient un code simple, puis utilisez son icône 🗑 ( Supprimer ) en haut à droite pour la supprimer – vous n’aurez pas besoin de ce code.
-
Dans le volet de l’explorateur Lakehouse sur la gauche, développez Fichiers et sélectionnez des produits pour afficher un nouveau volet affichant le fichier products.csv que vous avez téléchargé précédemment :
-
Dans le menu … de products.csv , sélectionnez Charger les données > Spark . Une nouvelle cellule de code contenant le code suivant doit être ajoutée au notebook :
df = spark.read.format("csv").option("header","true").load("Files/products/products.csv") # df now is a Spark DataFrame containing CSV data from "Files/products/products.csv". display(df)Astuce : Vous pouvez masquer le volet contenant les fichiers à gauche en utilisant son icône « . Cela vous aidera à vous concentrer sur le bloc-notes.
-
Utilisez le bouton ▷ ( Exécuter la cellule ) à gauche de la cellule pour l’exécuter.
Remarque : Comme c’est la première fois que vous exécutez du code Spark dans ce notebook, une session Spark doit être démarrée. Cela signifie que la première exécution peut prendre environ une minute. Les courses suivantes seront plus rapides.
-
Une fois la commande de cellule terminée, examinez le résultat sous la cellule, qui devrait ressembler à ceci :
Indice ID produit Nom du produit Catégorie Liste des prix 1 771 Montagne-100 Argent, 38 Vélo de montagne 3399.9900 2 772 Montagne-100 Argent, 42 Vélo de montagne 3399.9900 3 773 Montagne-100 Argent, 44 Vélo de montagne 3399.9900 … … … … …
4. Créer des tables delta
Vous pouvez enregistrer le dataframe en tant que table delta en utilisant la méthode saveAsTable. Delta Lake prend en charge la création de tables gérées et externes .
Créer une table gérée
Les tables gérées sont des tables pour lesquelles les métadonnées du schéma et les fichiers de données sont gérés par Fabric. Les fichiers de données de la table sont créés dans le dossier Tables .
- Sous les résultats renvoyés par la première cellule de code, utilisez le bouton + Code pour ajouter une nouvelle cellule de code si elle n’existe pas déjà. Entrez ensuite le code suivant dans la nouvelle cellule et exécutez-le :
df.write.format("delta").saveAsTable("managed_products") - Dans le volet de l’explorateur Lakehouse , dans le menu … du dossier Tables , sélectionnez Actualiser . Développez ensuite le nœud Tables et vérifiez que la table Managed_products a été créée.
Créer une table externe
Vous pouvez également créer des tables externes pour lesquelles les métadonnées du schéma sont définies dans le métastore du Lakehouse, mais les fichiers de données sont stockés dans un emplacement externe.
- Ajoutez une autre nouvelle cellule de code et ajoutez-y le code suivant :
df.write.format("delta").saveAsTable("external_products", path="abfs_path/external_products") - Dans le volet de l’explorateur Lakehouse , dans le menu … du dossier Fichiers , sélectionnez Copier le chemin ABFS .Le chemin ABFS est le chemin complet vers le dossier Fichiers dans le stockage OneLake de votre Lakehouse – similaire à ceci :abfss://workspace@tenant-onelake.dfs.fabric.microsoft.com/lakehousename.Lakehouse/Files
- Dans le code que vous avez entré dans la cellule de code, remplacez abfs_path par le chemin que vous avez copié dans le presse-papiers afin que le code enregistre le dataframe en tant que table externe avec des fichiers de données dans un dossier nommé external_products à l’emplacement de votre dossier Fichiers . Le chemin complet devrait ressembler à ceci :abfss://workspace@tenant-onelake.dfs.fabric.microsoft.com/lakehousename.Lakehouse/Files/external_products
- Dans le volet de l’explorateur Lakehouse , dans le menu … du dossier Tables , sélectionnez Actualiser . Développez ensuite le nœud Tables et vérifiez que la table external_products a été créée.
- Dans le volet de l’explorateur Lakehouse , dans le menu … du dossier Fichiers , sélectionnez Actualiser . Développez ensuite le nœud Fichiers et vérifiez que le dossier external_products a été créé pour les fichiers de données de la table.
Comparez les tables gérées et externes
Explorons les différences entre les tables gérées et externes.
- Ajoutez une autre cellule de code et exécutez le code suivant :
%%sql DESCRIBE FORMATTED managed_products;Dans les résultats, affichez la propriété Location de la table, qui doit être un chemin d’accès au stockage OneLake pour le Lakehouse se terminant par /Tables/managed_products (vous devrez peut-être élargir la colonne Type de données pour voir le chemin complet).
- Modifiez la
DESCRIBEcommande pour afficher les détails de la table external_products comme indiqué ici :%%sql DESCRIBE FORMATTED external_products;Dans les résultats, affichez la propriété Location de la table, qui doit être un chemin d’accès au stockage OneLake pour le Lakehouse se terminant par /Files/external_products (vous devrez peut-être élargir la colonne Type de données pour voir le chemin complet).
Les fichiers de la table gérée sont stockés dans le dossier Tables du stockage OneLake du Lakehouse. Dans ce cas, un dossier nommé Managed_products a été créé pour stocker les fichiers Parquet et le dossier delta_log pour la table que vous avez créée.
- Ajoutez une autre cellule de code et exécutez le code suivant :
%%sql DROP TABLE managed_products; DROP TABLE external_products; - Dans le volet de l’explorateur Lakehouse , dans le menu … du dossier Tables , sélectionnez Actualiser . Développez ensuite le nœud Tables et vérifiez qu’aucune table n’est répertoriée.
- Dans le volet de l’explorateur Lakehouse , développez le dossier Fichiers et vérifiez que les produits_externes n’ont pas été supprimés. Sélectionnez ce dossier pour afficher les fichiers de données Parquet et le dossier _delta_log pour les données qui se trouvaient auparavant dans la table external_products . Les métadonnées de la table externe ont été supprimées, mais les fichiers n’ont pas été affectés.
Utiliser SQL pour créer une table
- Ajoutez une autre cellule de code et exécutez le code suivant :
%%sql CREATE TABLE products USING DELTA LOCATION 'Files/external_products'; - Dans le volet de l’explorateur Lakehouse , dans le menu … du dossier Tables , sélectionnez Actualiser . Développez ensuite le nœud Tables et vérifiez qu’une nouvelle table nommée products est répertoriée. Développez ensuite la table pour vérifier que son schéma correspond à la trame de données d’origine enregistrée dans le dossier external_products .
- Ajoutez une autre cellule de code et exécutez le code suivant :
%%sql SELECT * FROM products;
5. Explorer la gestion des versions de table
L’historique des transactions pour les tables delta est stocké dans des fichiers JSON dans le dossier delta_log . Vous pouvez utiliser ce journal des transactions pour gérer la gestion des versions des données.
-
Ajoutez une nouvelle cellule de code au notebook et exécutez le code suivant :
%%sql UPDATE products SET ListPrice = ListPrice * 0.9 WHERE Category = 'Mountain Bikes';Ce code met en place une réduction de 10% sur le prix des VTT.
-
Ajoutez une autre cellule de code et exécutez le code suivant :
%%sql DESCRIBE HISTORY products;Les résultats montrent l’historique des transactions enregistrées pour la table.
-
Ajoutez une autre cellule de code et exécutez le code suivant :
delta_table_path = 'Files/external_products' # Get the current data current_data = spark.read.format("delta").load(delta_table_path) display(current_data) # Get the version 0 data original_data = spark.read.format("delta").option("versionAsOf", 0).load(delta_table_path) display(original_data)Les résultats affichent deux dataframe: l’une contenant les données après la réduction de prix et l’autre montrant la version originale des données.
6. Utiliser des tables delta pour diffuser des données
Delta Lake prend en charge le streaming de données. Les tables Delta peuvent être un récepteur ou une source pour les flux de données créés à l’aide de l’API Spark Structured Streaming. Dans cet exemple, vous utiliserez une table delta comme récepteur pour certaines données de streaming dans un scénario d’Internet des objets (IoT) simulé.
- Ajoutez une nouvelle cellule de code dans le bloc-notes. Ensuite, dans la nouvelle cellule, ajoutez le code suivant et exécutez-le :

- Assurez-vous que le message Flux source créé… est imprimé. Le code que vous venez d’exécuter a créé une source de données en streaming basée sur un dossier dans lequel certaines données ont été enregistrées, représentant les lectures d’appareils IoT hypothétiques.
- Dans une nouvelle cellule de code, ajoutez et exécutez le code suivant :
# Write the stream to a delta table delta_stream_table_path = 'Tables/iotdevicedata' checkpointpath = 'Files/delta/checkpoint' deltastream = iotstream.writeStream.format("delta").option("checkpointLocation", checkpointpath).start(delta_stream_table_path) print("Streaming to delta sink...")Ce code écrit les données du périphérique de streaming au format delta dans un dossier nommé iotdevicedata . En raison du chemin d’accès à l’emplacement du dossier dans le dossier Tables , une table sera automatiquement créée pour celui-ci.
- Dans une nouvelle cellule de code, ajoutez et exécutez le code suivant :
%%sql SELECT * FROM IotDeviceData;Ce code interroge la table IotDeviceData , qui contient les données de l’appareil provenant de la source de streaming.
- Dans une nouvelle cellule de code, ajoutez et exécutez le code suivant :
# Add more data to the source stream more_data = '''{"device":"Dev1","status":"ok"} {"device":"Dev1","status":"ok"} {"device":"Dev1","status":"ok"} {"device":"Dev1","status":"ok"} {"device":"Dev1","status":"error"} {"device":"Dev2","status":"error"} {"device":"Dev1","status":"ok"}''' mssparkutils.fs.put(inputPath + "more-data.txt", more_data, True)Ce code écrit davantage de données hypothétiques sur l’appareil dans la source de streaming.
- Réexécutez la cellule contenant le code suivant :
%%sql SELECT * FROM IotDeviceData;Ce code interroge à nouveau la table IotDeviceData , qui doit désormais inclure les données supplémentaires ajoutées à la source de streaming.
- Dans une nouvelle cellule de code, ajoutez et exécutez le code suivant :
deltastream.stop()Ce code arrête le flux.
7. Nettoyer les ressources
Dans cet exercice, vous avez appris à utiliser des tables delta dans Microsoft Fabric.
Si vous avez fini d’explorer votre Lakehouse, vous pouvez supprimer l’espace de travail que vous avez créé pour cet exercice.
- Dans la barre de gauche, sélectionnez l’icône de votre espace de travail pour afficher tous les éléments qu’il contient.
- Dans le menu … de la barre d’outils, sélectionnez Paramètres de l’espace de travail .
- Dans la section Autre , sélectionnez Supprimer cet espace de travail .
Note : Source https://learn.microsoft.com/
Aller plus loin
L’analytique dans Microsoft Fabric vous interesse? Passez au niveau supérieur, obtenez la certification DP 600 en suivant le parcours de formation en ligne offert gratuitement par Microsoft sur son site d’apprentissage officiel.
Vous pouvez y accéder directement via ce lien😉 : https://learn.microsoft.com/fr-fr/credentials/certifications/exams/dp-600/

Créer un bouton pour exporter les données du visuel PowerBI vers Excel ou CSV

Découvrir la DataScience dans Microsoft Fabric

Organisez votre lakehouse Fabric à l’aide de la conception d’architecture en médaillon

Ingérer des données avec des notebooks Spark et Microsoft Fabric

Bien démarrer avec les entrepôts de données dans Microsoft Fabric

La version d’essai de Microsoft Fabric à nouveau disponible

Analysez les données avec Apache Spark

Bien démarrer avec les Lakehouses dans Fabric

Activez et utilisez Microsoft Fabric
